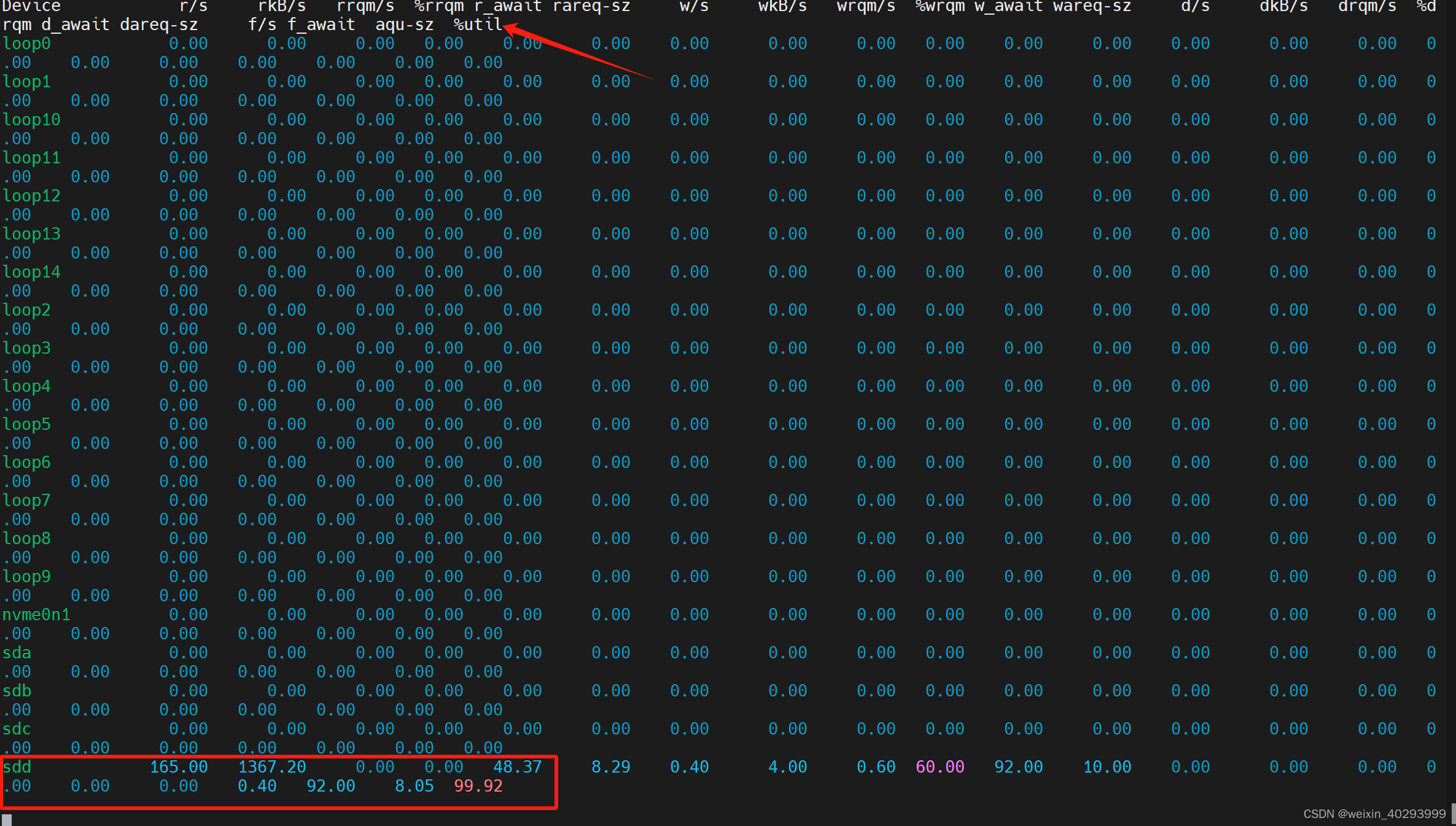
使用的命令:iostat -x 5
可以看到 ssd的利用率已经满了。
之前在的数据集放在了 hdd上,训练结果特别慢。
所以我把它移动到了ssd上,然后训练参数用的 resume,
但是!!!!它把历史记住了,仍然不从ssd上来取数据。
配置文件的路径也换了,但它还是会去找旧的。
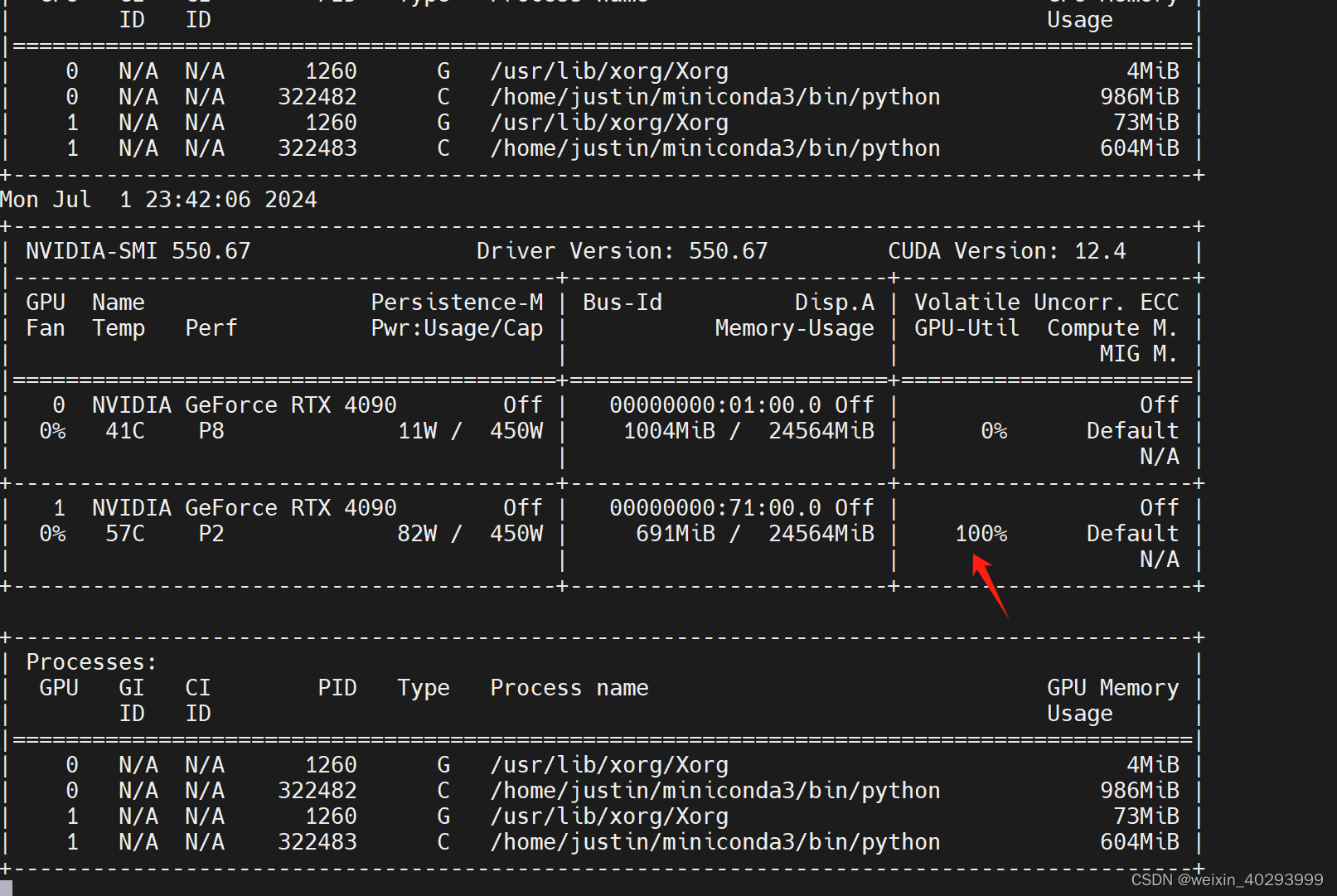
现在的100% 是扫描数据的100%
因数数据集15G~20G,还是比较多的。
engine/trainer: task=detect, mode=train, model=/home/justin/Desktop/code/python_project/Jersey-Number/yolov8n.pt, data=/home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/data.yaml, epochs=1000, time=None, patience=100, batch=64, imgsz=640, save=True, save_period=-1, cache=False, device=[0, 1], workers=8, project=None, name=train70, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs/detect/train70
Overriding model.yaml nc=80 with nc=4
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
19 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 1 493056 ultralytics.nn.modules.block.C2f [384, 256, 1]
22 [15, 18, 21] 1 752092 ultralytics.nn.modules.head.Detect [4, [64, 128, 256]]
Model summary: 225 layers, 3011628 parameters, 3011612 gradients, 8.2 GFLOPs
Transferred 319/355 items from pretrained weights
DDP: debug command /home/justin/miniconda3/bin/python -m torch.distributed.run --nproc_per_node 2 --master_port 41127 /home/justin/.config/Ultralytics/DDP/_temp_uog7ddsr140402595641744.py
WARNING:__main__:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
Ultralytics YOLOv8.2.1 🚀 Python-3.11.0 torch-2.3.0+cu121 CUDA:0 (NVIDIA GeForce RTX 4090, 24210MiB)
CUDA:1 (NVIDIA GeForce RTX 4090, 24188MiB)
TensorBoard: Start with 'tensorboard --logdir runs/detect/train70', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=4
Transferred 319/355 items from pretrained weights
Freezing layer 'model.22.dfl.conv.weight'
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
/home/justin/miniconda3/lib/python3.11/site-packages/torch/nn/modules/conv.py:456: UserWarning: Plan failed with a cudnnException: CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR: cudnnFinalize Descriptor Failed cudnn_status: CUDNN_STATUS_NOT_SUPPORTED (Triggered internally at ../aten/src/ATen/native/cudnn/Conv_v8.cpp:919.)
return F.conv2d(input, weight, bias, self.stride,
AMP: checks passed ✅
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
train: Scanning /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/
我就是看这里:
train: WARNING ⚠️ /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/images/284193,42a000df17be3d.jpg: 1 duplicate labels removed
train: WARNING ⚠️ /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/images/284193,575c000f3f01e40.jpg: 1 duplicate labels removed
train: WARNING ⚠️ /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/images/284193,70d2000c58fbf86.jpg: 1 duplicate labels removed
train: WARNING ⚠️ /home/justin/Desktop/code/python_project/Jersey-Number/datasets/20240511_four_in_1/data_head_person_hoop_number/train/images/284193,880000198e8148.jpg: 1 duplicate labels removed
看出路径不对了,然后from scratch开始训练,就好使了。
然而并无卵用,确实换到ssd上了,还是很差,应该是碎文件所致,哎。。。所以,深度学习级别的hello world 用plk存储文件是有道理的,为了不让他那么碎啊 =====个人理解啊。